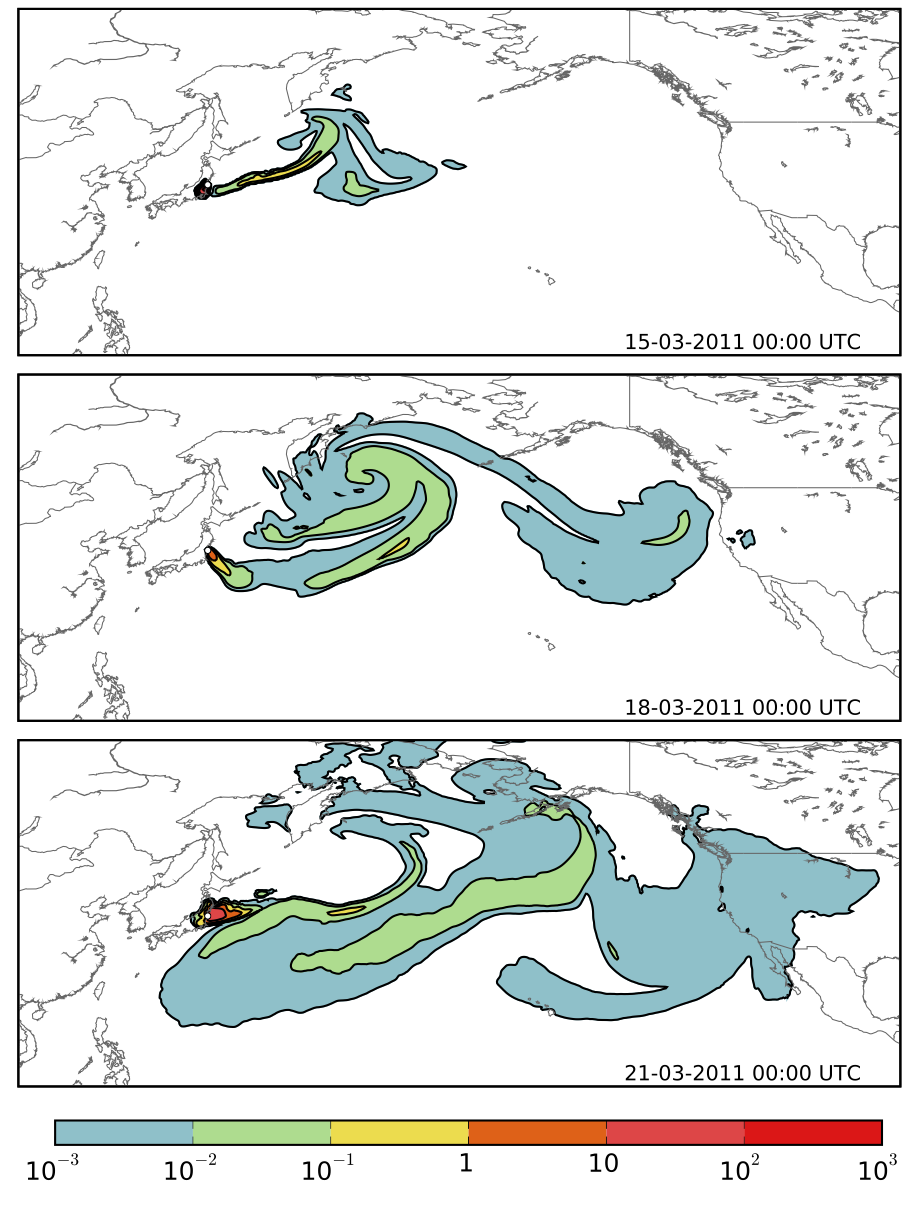
Dispersion atmosphérique simulée du panache de césium-137 (en Becquerel par mètre cube) émis par la centrale de Fukushima Daiichi en mars 2011.
Dans l’éventualité d’un rejet accidentel de polluants dans l’atmosphère, il est important de connaître et de prévoir les zones contaminées, notamment afin de mettre en œuvre les mesures nécessaires à la protection des populations. Pour cela, des modèles numériques sont utilisés pour simuler la dispersion atmosphérique des polluants. La figure ci-contre représente la dispersion atmosphérique à grande échelle du panache radioactif de césium-137 émise lors de l’accident nucléaire de Fukushima, telle que simulée par le modèle POLYPHEMUS/POLAIR3D
Ces modèles ont besoin de données d’entrée, dont les plus importantes en situation accidentelle sont les champs de vent, les précipitations et le terme source de polluants. Une mauvaise connaissance de ces entrées entraînent des erreurs et des incertitudes sur les concentrations de polluants simulées et obtenues en sortie de modèle. Or du fait du caractère exceptionnel et unique d’un rejet accidentel et de l’impossibilité d’approcher le lieu du rejet, le terme source à l’origine de la pollution, est en général très difficile à connaître.
Par ailleurs un certain nombre d’observations, qui mesurent la concentration de polluants en des points précis, sont rapidement disponibles. Ces observations peuvent être utilisées pour évaluer la précision du modèle, mais on peut également les utiliser pour corriger ou estimer les données d’entrée du modèle, et en particulier le terme source, par des méthodes dites de modélisation inverse. Quand le lieu du rejet est connu, comme dans le cas de l’accident de Fukushima Dai-ichi, l’estimation du terme source consiste à déterminer les quantités de polluants rejetées et leur évolution dans le temps.
Les méthodes mathématiques de modélisation inverse utilisent l’information contenue dans les observations pour remonter, grâce au modèle numérique, jusqu’au terme source. Plus le nombre d’observations est grand et plus l’estimation du terme source sera précise. C’est pourquoi, afin d’utiliser le plus grand nombre d’observations, il peut être bénéfique d’utiliser dans la même inversion plusieurs types de données : des mesures de concentration de polluants dans l’air, déposés au sol, etc. Des méthodes statistiques sont alors utilisées pour équilibrer objectivement le poids de chacun de ces jeux de données dans l’inversion.
Une fois le terme source estimé, le modèle numérique de dispersion permet de simuler les zones contaminées à court terme par le nuage de polluants et à long terme par les polluants déposés au sol. La figure ci-dessous compare les observation de dépôts cumulés près de la centrale à la simulation sur toute la période de l’accident. Les résultats de cette simulation ont été validés via une intercomparison internationale organisée par le Conseil Scientifique du Japon. Ils sont en très bon accord avec des données indépendantes, c’est-à-dire qui n’ont pas été utilisées dans l’inversion.
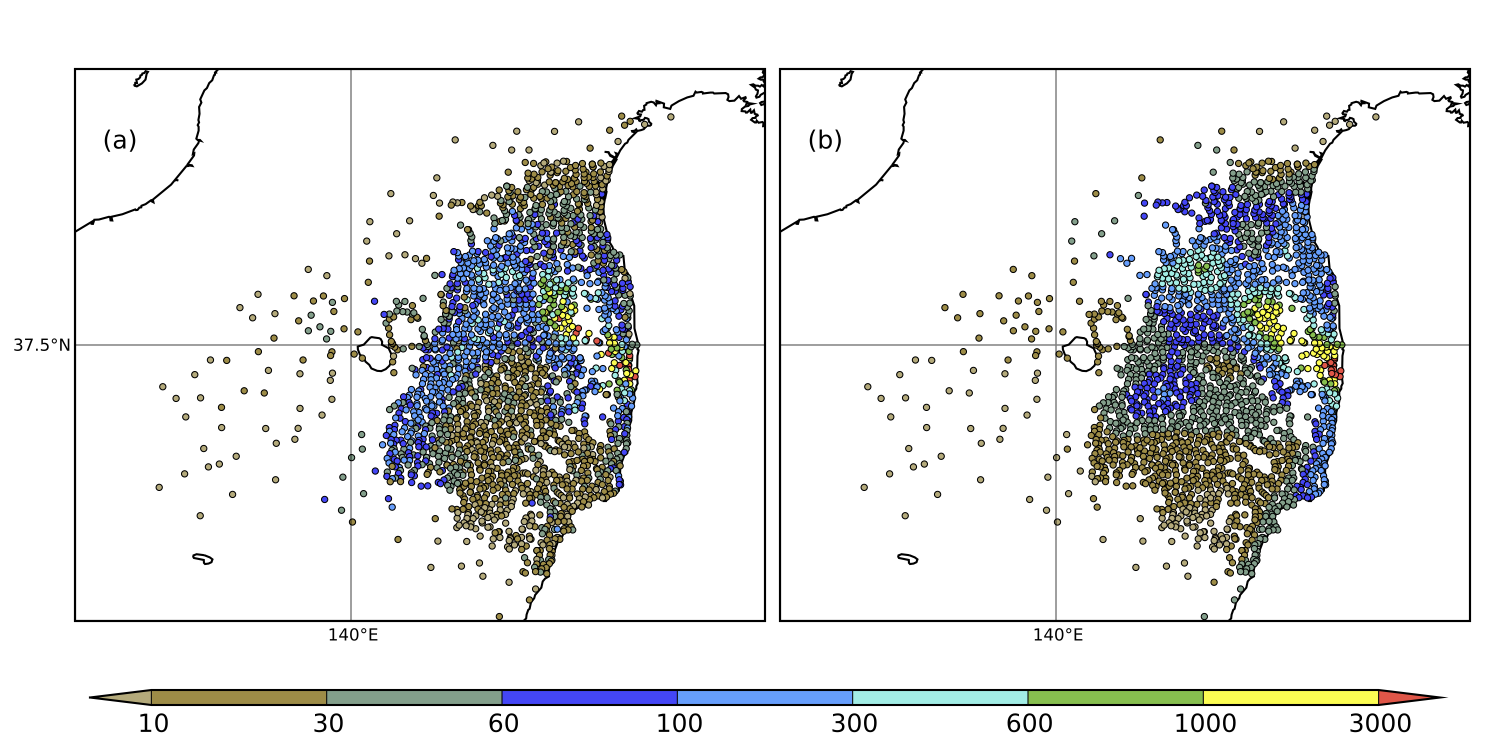
Dépôts de césium-137 (en kilo Becquerel par mètre carré) mesurés (à gauche) et simulés (à droite) autour de la centrale de Fukushima Dai-ichi.
Brève rédigée par Victor Winiarek et Marc Bocquet (École des Ponts ParisTech, CEREA).
Pour en savoir plus :
- Revue Pollution Atmosphérique – Climat, Santé, Société. Hors série de Septembre 2010 – Retour aux sources : La recherche et l’identification des sources de pollution
- [en anglais] Page web du CEREA sur l’accident de Fukushima Daiichi
- A. Mathieu et al., État de la modélisation pour simuler l’accident nucléaire de la centrale de Fukushima Daiichi. Pollution Atmosphérique, 217, 2013.
- [en anglais] V. Winiarek, M. Bocquet, N. Duhanyan, Y. Roustan, O. Saunier, et A. Mathieu. Estimation of the caesium-137 source term from the Fukushima Daiichi nuclear power plant using a consistent joint assimilation of air concentration and deposition observations. Atmos. Env., 82, 268-279, 2014.
Crédits Images : Victor Winiarek et Marc Bocquet.


2 Commentaires