Vue de Paris depuis la Tour Montparnasse le 12 décembre 2013
Les géophysiciens comme les météorologues ou les océanographes travaillent avec de complexes modèles mathématiques qui mettent en équation la physique des fluides (atmosphère, océan).
Les équations du modèle sont résolus numériquement en affectant, pour chaque grandeur physique, une valeur à chaque maille d’une grille, qui est un maillage du domaine spatial étudié. Par exemple, dans un modèle de qualité de l’air destiné à simuler des concentrations de polluants, une valeur de la concentration de chacun des polluants est attribuée à chaque maille.

La simulation numérique du polluant (sans (rouge) ou avec (vert) assimilation d’observations)
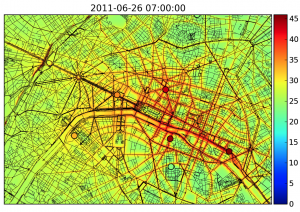
est difficilement capable de rendre compte des fluctuations sous-maille de concentration observées par la mesure directe.
Une autre manière d’étudier la concentration d’un polluant est de la mesurer. Les mesures faites au sol sont généralement précises. Cependant elles ne sont représentatives que d’un domaine restreint autour du site de mesure. Différemment, le modèle numérique simule une valeur de concentration de polluant qui représente une moyenne pour la maille qui contient le site de mesure. Il parait donc difficile de comparer mesure locale et valeur moyenne sur la maille, particulièrement si la quantité observée présente de grandes fluctuations spatiales et temporelles au sein de la maille.
Cette inadéquation entre valeurs obtenues par la mesure et valeurs obtenues par les modèles numériques est appelée erreur de représentativité (figure ci-contre).
Or les mesures sont utilisées pour constamment recaler les modèles de prévision qui ont tendance à s’éloigner de la réalité. Ce processus est connu sous le nom d’assimilation de données. Identifiée comme une des premières source d’erreur en assimilation de données, et très souvent supérieure à l’erreur typique des instruments de mesure, l’erreur de représentativité est très difficile à estimer. Plusieurs méthodes mathématiques faisant appel aux statistiques ont cependant été proposées.
Parmi elles, la méthode dite de descente d’échelle cherche à construire, pour chaque site de mesure, un modèle statistique très simple reliant les résultats du modèle numérique sur cette maille au site d’observation ciblé dans la maille. Ce modèle statistique est construit en minimisant l’écart entre modèle et observations d’un site particulier sur une longue période d’apprentissage. Ce type de méthode permet de capturer de l’information à un niveau de détails plus fin que la maille du modèle numérique (on dit sous-maille), et donc d’estimer l’erreur de représentativité.
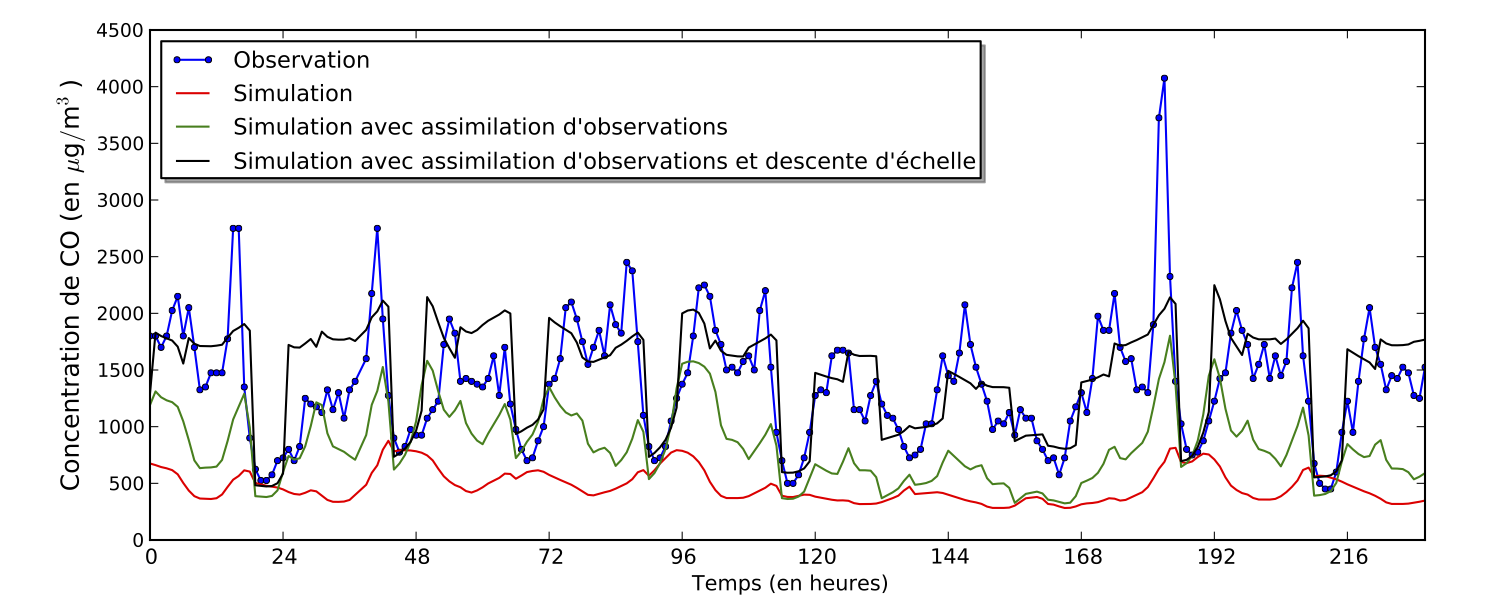
Observations et simulations de concentration de monoxyde de carbone (CO) à la station Paris-Auteuil d’AirParif.
La figure ci-dessus illustre l’application de la descente d’échelle à l’assimilation de données de monoxyde de carbone (CO) dans un modèle de qualité de l’air, de maille 25km par 25km, afin de corriger les erreurs de représentativité. Les pics de monoxyde de carbone sont dus à des sources très locales comme le trafic routier, les usines, ou le chauffage urbain, et le modèle numérique de qualité de l’air ne les représente que très grossièrement et imparfaitement. L’utilisation d’un modèle statistique de descente d’échelle (courbe noire) permet de corriger fortement l’impact néfaste de cette erreur de représentativité comparé au modèle numérique (en rouge et en vert).
Brève rédigée par Marc Bocquet et Mohammad Reza Koohkan
Pour en savoir plus :
- Brèves connexes : Navier et ces drôles d’oiseaux, Votre air, votre santé, Ignorer la météo d’hier, c’est aussi louper celle de demain, Prévoir les crues – Avec quelle incertitude ? Comment zoomer le climat ?
- [en anglais] M. R. Koohkan et M. Bocquet. Accounting for representativeness errors in the inversion of atmospheric constituent emissions: Application to the retrieval of regional carbon monoxide fluxes. Tellus B, 64, 19047, 2012.
- [en anglais] M. R. Koohkan. Multiscale data assimilation approaches and error characterisation applied to the inverse modelling of atmospheric constituent emission fields. Thèse de doctorat de l’Université Paris-Est.
- Cours d’assimilation de F. Bouttier (météo) en Master 2
Crédits Images : Marc Bocquet, MPT2013