Nous ne pouvons plus nous passer des prévisions météorologiques.
Les prévisions météorologiques font partie de notre quotidien et sont devenues un élément essentiel de notre mode de vie. Elles sont effectuées à partir de simulations numériques du comportement de l’atmosphère. Les résultats de ces modélisations numériques se trouvent entachés d’erreurs ayant de multiples origines : méconnaissance de certains phénomènes physiques, incertitudes sur l’état de l’atmosphère, approximations introduites par les algorithmes utilisés, etc.
La complexité des informations fournies par ces simulations numériques (typiquement une dizaine de millions de valeurs prévues pour la température, la pression, le vent et d’autres encore sur l’ensemble du globe terrestre pour chaque échéance de prévision) rend parfois difficile la détermination de l’origine exacte de ces erreurs. Une manière couramment employée pour améliorer les prévisions météorologiques consiste à trouver un lien statistique entre la situation météorologique prévue et la météorologie effectivement observée.
De manière générale, la situation météorologique est décrite par plusieurs grandeurs (température de l’air, vitesse du vent, période de l’année, etc.). Des méthodes statistiques vont tenter de les relier de manière systématique au temps réellement observé par le passé. Ainsi, on sait que lors d’épisodes de vent d’Autan, la température prévue par certains modèles a tendance à être inférieure à la température qui sera effectivement mesurée. Encore faut-il savoir de combien ! Ces sont ces méthodes statistiques qui permettent de le quantifier. Parmi ces nombreuses méthodes dites de fouille de données, les plus modernes portent des noms évocateurs comme réseaux de neurones, poétiques comme forêts aléatoires ou plus mystérieux encore comme séparateurs à vaste marge.
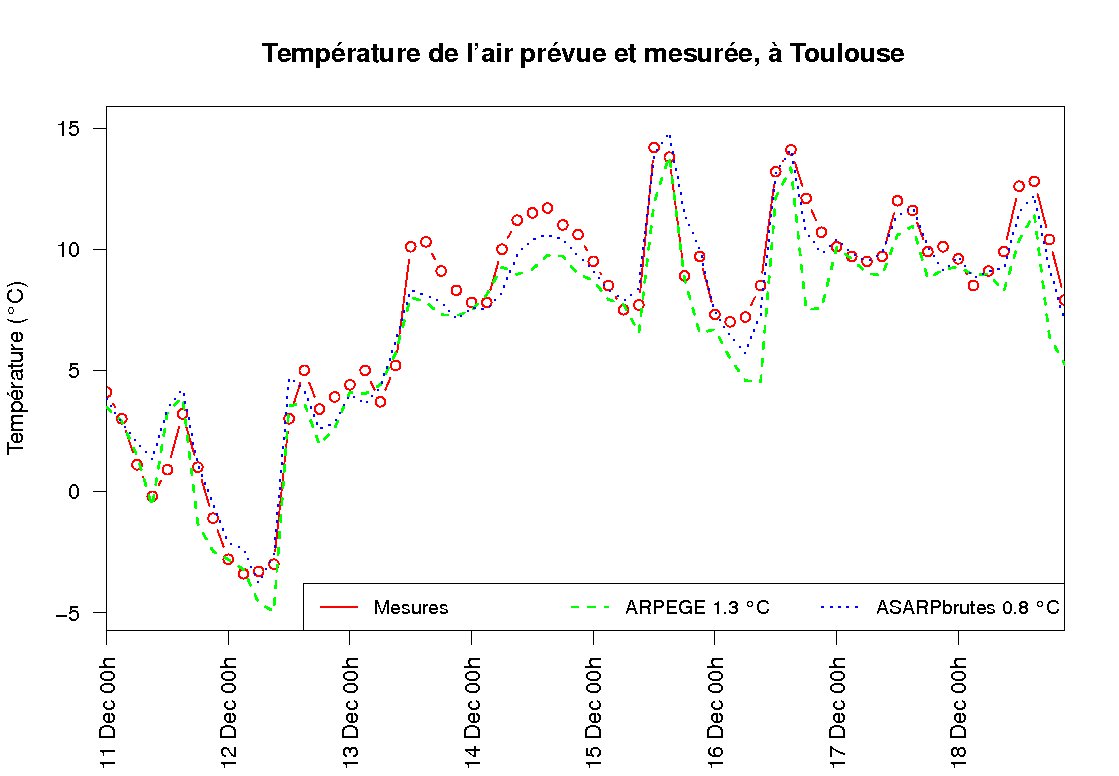
Adaptation statistique de la courbe de température à Toulouse entre le 11 et le 18 décembre 2012
A titre d’exemple, la figure ci-dessus montre la température mesurée toutes les trois heures à Toulouse entre le 11 et le 18 décembre 2012 (courbe et points rouges). La prévision issue du modèle numérique ARPEGE de Météo-France est tracée en tirets verts. Cette courbe reproduit bien l’évolution de la température mesurée et on peut calculer qu’en moyenne la température prévue s’écarte de la température mesurée de 1,3°C. En appliquant une statistique de base appelée régression linéaire multiple, qui utilise notamment la température prévue par ARPEGE, on obtient une autre prévision (courbe en pointillés bleus) plus proche de la valeur effectivement mesurée : l’erreur commise en moyenne n’est plus que de 0,8 °C. En pratique toutefois, il peut arriver que cette nouvelle prévision, appelée adaptation statistique, soit moins bonne que la prévision du modèle numérique. C’est le cas ici pour la journée du 11 décembre : la courbe verte se situe parfois plus près de la courbe rouge que la bleue. Mais sur le long terme, on peut affirmer que la méthode statistique améliore notablement la prévision initiale et c’est la série corrigée qui est diffusée au public.
Des prévisions de température, de vent, ou de concentration en ozone par exemple sont ainsi statistiquement améliorées et employées tous les jours. Elles permettent par exemple de disposer de meilleures prévisions en matière de consommation d’électricité, de production d’électricité éolienne, ou de s’appuyer sur des informations plus fiables pour les décisions de santé publique en matière de risque sanitaire lié à la pollution à l’ozone ou à des épisodes de fortes chaleurs.
Brève rédigée par Michael Zamo (Meteo-France) d’après les travaux de la direction de la production de Météo France.
Pour en savoir plus :
- « Vents et nuages », Dossier Pour la science, numéro 78, janvier-mars 2013.
- Page web fouille de données, de Philippe Besse, professeur à l’INSA.
- S. Tufféry (2012), « Data Mining et Statistique décisionnelle : l’intelligence des données », Éditions Technip.
- P. Besse, H. Milhem, O.Mestre, A.Dufour, V.H.Peuch (2007), « Comparaison de techniques de « Data Mining » pour l’adaptation statistique des prévisions d’ozone du modèle de chimie-transport MOCAGE », Pollution atmosphérique A, vol. 49, n° 195, pp. 285-292.
- « Correction des prévisions de l’ozone par adaptation statistique », plate-forme de modélisation régionale Iris, AIR pays de la Loire, (2008).
- Brève connexe : Pourquoi corriger les séries climatiques?
Crédits Images : Météo-France.




2 Commentaires